

特長
VoiceTagging (ボイスタギング)とは
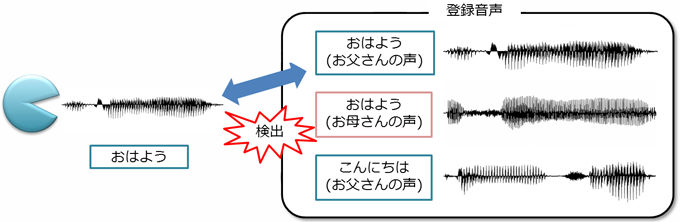
登録した同じ言葉を別々の人が発話すると、話者を特定します。
同じキーワードを発声しても、話者によってその後のアクションを分けるような使い方が可能です。
【 PepperによるVoiceTaggingデモ 】
主な特長
- 登録した本人が同じ言葉を話したときのみ検出します。
- 登録した本人以外が同じ言葉を話しても検出しません。
- 登録は音声で行います。
従来の音声認識技術との違い
| 項目 | VoiceTagging | 従来の音声認識 |
|---|---|---|
| 事前登録 | 音声で単語登録 | キーボードから辞書登録 |
| 多言語対応 | 言語非依存 | 言語ごとに認識辞書を用意 |
| 検出対象の話者 | 登録話者の発声のみを検出 | 話者に関係なく認識 |
| 検出精度 | 小語彙に優れ、マイクの音質に依存しない (登録時と同じデバイスを使う) |
大語彙に優れ、ある程度の音質を必要とする |
| 処理量 | 従来の20%程の処理量 | PC~サーバークラス |